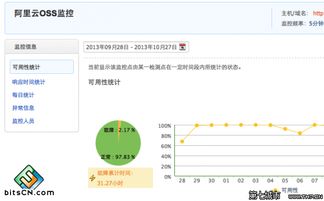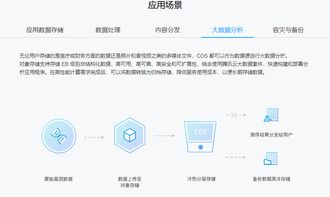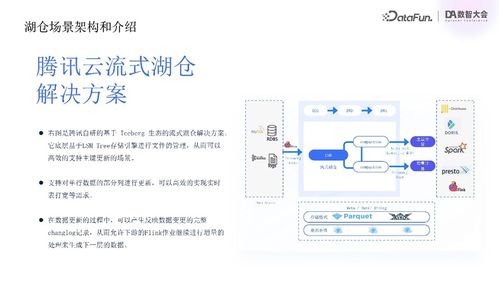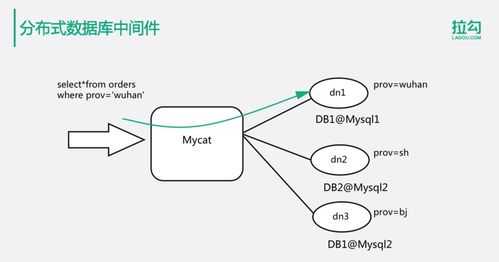
隨著數(shù)字化轉型的深入,后端數(shù)據(jù)庫技術已從單一的關系型數(shù)據(jù)庫發(fā)展為多元化的生態(tài)系統(tǒng),以滿足不同場景下的數(shù)據(jù)處理與存儲需求。當前主流的數(shù)據(jù)庫選擇和實踐呈現(xiàn)出明顯的分層和場景化特征。
一、核心存儲層:關系型與非關系型并存
1. 關系型數(shù)據(jù)庫(RDBMS)仍是中流砥柱
- MySQL/PostgreSQL:作為開源領域的雙雄,MySQL憑借其成熟生態(tài)和性能優(yōu)勢,在Web應用中占據(jù)主導地位;PostgreSQL則以其強大的功能(如JSON支持、GIS擴展)、嚴格的SQL標準兼容性和可擴展性,在復雜業(yè)務系統(tǒng)和新興應用中快速增長。
- 云托管服務:AWS RDS、Google Cloud SQL、Azure Database等云服務提供了免運維、自動備份、讀寫分離等托管能力,大幅降低了運維成本。
2. 非關系型數(shù)據(jù)庫(NoSQL)的多元化發(fā)展
- 文檔數(shù)據(jù)庫:MongoDB因其靈活的JSON-like文檔模型和強大的查詢能力,成為處理半結構化數(shù)據(jù)(如用戶配置、內(nèi)容管理)的熱門選擇。
- 鍵值存儲:Redis作為內(nèi)存數(shù)據(jù)庫,以其超高性能支撐緩存、會話存儲和實時排行榜等場景;Amazon DynamoDB則在云原生分布式鍵值存儲領域表現(xiàn)突出。
- 寬列存儲:Cassandra和ScyllaDB為海量時間序列數(shù)據(jù)、物聯(lián)網(wǎng)數(shù)據(jù)提供高寫入吞吐和線性擴展能力。
- 圖數(shù)據(jù)庫:Neo4j在處理社交關系、推薦系統(tǒng)、欺詐檢測等高度關聯(lián)數(shù)據(jù)時具有天然優(yōu)勢。
二、數(shù)據(jù)處理與分析層:實時與批處理的融合
1. 數(shù)據(jù)倉庫的現(xiàn)代化演進
- 云數(shù)倉成為主流:Snowflake、Google BigQuery、Amazon Redshift等完全托管的云數(shù)倉,實現(xiàn)了存儲與計算分離,支持PB級數(shù)據(jù)的快速分析。
- 實時數(shù)倉興起:Apache Druid、ClickHouse等OLAP數(shù)據(jù)庫能夠對實時流數(shù)據(jù)進行亞秒級查詢,滿足監(jiān)控、BI等實時分析需求。
2. 流處理平臺的集成
- Apache Kafka不僅作為消息隊列,其Kafka Streams和KSQL提供了實時流處理能力,形成“事件流中心”。
- Apache Flink憑借其精確一次處理語義和低延遲特性,成為復雜事件處理和實時ETL的重要選擇。
三、新興趨勢與架構模式
1. 多模型與多數(shù)據(jù)庫并存
現(xiàn)代架構常采用“多數(shù)據(jù)庫”策略,根據(jù)數(shù)據(jù)特性選擇最佳存儲。例如:用戶關系用圖數(shù)據(jù)庫、會話數(shù)據(jù)用Redis、交易記錄用PostgreSQL、日志用Elasticsearch,通過服務化接口統(tǒng)一訪問。
2. 云原生與Serverless數(shù)據(jù)庫
Amazon Aurora、Azure Cosmos DB等云原生數(shù)據(jù)庫提供了全球分布、自動擴展等能力;Serverless數(shù)據(jù)庫(如Amazon Aurora Serverless)實現(xiàn)了按使用量計費,進一步優(yōu)化資源利用率。
3. 數(shù)據(jù)網(wǎng)格與去中心化治理
數(shù)據(jù)網(wǎng)格(Data Mesh)理念倡導將數(shù)據(jù)視為產(chǎn)品,由領域團隊負責其生命周期,推動了數(shù)據(jù)庫管理的去中心化,強調標準化接口而非統(tǒng)一技術棧。
四、存儲支持服務的全面化
1. 備份與容災
- 跨區(qū)域復制、時間點恢復(PITR)成為云數(shù)據(jù)庫標準功能。
- 工具如Percona XtraBackup、pgBackRest提供物理備份能力。
2. 監(jiān)控與可觀測性
- Prometheus + Grafana監(jiān)控數(shù)據(jù)庫性能指標。
- 慢查詢分析工具(如pt-query-digest、pgstatstatements)持續(xù)優(yōu)化性能。
3. 遷移與同步工具
- Debezium實現(xiàn)CDC(變更數(shù)據(jù)捕獲),將數(shù)據(jù)庫變更實時流式同步到數(shù)據(jù)倉庫或緩存。
- AWS DMS、Google Database Migration Service簡化上云遷移。
五、選型建議與實踐考量
選擇數(shù)據(jù)庫時需綜合評估:
- 數(shù)據(jù)模型:結構化程度、關系復雜度。
- 訪問模式:讀寫比例、事務需求、并發(fā)量。
- 一致性要求:強一致性還是最終一致性。
- 擴展性:垂直擴展還是水平分片。
- 生態(tài)與團隊技能:社區(qū)活躍度、工具鏈成熟度。
###
現(xiàn)代后端數(shù)據(jù)庫生態(tài)已從“一刀切”走向“場景驅動”,形成了關系型、NoSQL、數(shù)據(jù)倉庫、流處理平臺協(xié)同工作的多層次架構。成功的實踐不在于追求最新技術,而在于根據(jù)業(yè)務特性選擇合適工具,并通過有效的治理與運維保障數(shù)據(jù)可靠性、安全性和性能。隨著AI增強管理、自動化優(yōu)化等技術的發(fā)展,數(shù)據(jù)庫將更加智能化和隱形化,讓開發(fā)者更專注于業(yè)務邏輯創(chuàng)新。